State of Node.js Performance 2023
The year is 2023 and we’ve released Node.js v20. It’s a significant accomplishment, and this article aims to use scientific numbers to assess the state of Node.js’ performance.
All the benchmark results contain a reproducible example and hardware details. To reduce the noise for regular readers, the reproducible steps will be collapsed at the beginning of all sections.
This article aims to provide a comparative analysis of different versions of Node.js. It highlights the improvements and setbacks and provides insights into the reasons behind those changes, without drawing any comparisons with other JavaScript runtimes.
To conduct this experiment, we utilized Node.js versions 16.20.0, 18.16.0, and 20.0.0, and divided the benchmark suites into three distinct groups:
- Node.js Internal Benchmark
Given the significant size and time-consuming nature of the Node.js benchmark suite, I have selectively chosen
benchmarks that, in my opinion, have a greater impact on Node.js developers and configurations, such as reading a file
with 16 MB using fs.readfile. These benchmarks are grouped by modules, such as fs and streams. For additional
details on the Node.js benchmark suite, please refer to the
Node.js source code.
I maintain a repository called nodejs-bench-operations that
includes benchmark operations for all major versions of Node.js, as well as the last three releases of each version
line. This allows for easy comparison of results between different versions, such as Node.js v16.20.0 and v18.16.0, or
v19.8.0 and v19.9.0, with the objective of identifying regressions in the Node.js codebase. If you are interested in
Node.js comparisons, following this repository might be beneficial (and don’t forget to give it a star if you find it
helpful).
- HTTP Servers (Frameworks)
This practical HTTP benchmark sends a significant number of requests to various routes, returning JSON, plain text, and
errors, taking express and fastify as references. The primary objective is to determine if the results obtained from
the Node.js Internal Benchmark and nodejs-bench-operations are
applicable to common HTTP applications.
💡 UPDATE: Due to the extensive content covered in this article, the third and final step will be shared in a subsequent article. To stay updated and receive notifications, I encourage you to follow me on Twitter/LinkedIn.
Environment
To perform this benchmark, an AWS Dedicated Host was used with the following computing-optimized instance:
- c6i.xlarge (Ice Lake) 3,5 GHz - Computing Optimized
- 4 vCPUs
- 8 GB Mem
- Canonical, Ubuntu, 22.04 LTS, amd64 jammy
- 1GiB SSD Volume Type
Node.js Internal Benchmark
The following modules/namespaces were selected in this benchmark:
-
fs- Node.js file system -
events- Node.js event classesEventEmitter/EventTarget -
http- Node.js HTTP server + parser -
misc- Node.js startup time usingchild_processesandworker_threads+trace_events -
module- Node.jsmodule.require -
streams- Node.js streams creation, destroy, readable and more -
url- Node.js URL parser -
buffers- Node.js Buffer operations -
util- Node.js text encoder/decoder
And the configurations used are available at RafaelGSS/node#state-of-nodejs and all the results were published in the main repository: State of Node.js Performance 2023.
Node.js benchmark approach
Before presenting the results, it is crucial to explain the statistical approach used to determine the confidence of the benchmark results. This method has been explained in detail in a previous blog post, which you can refer to here: Preparing and Evaluating Benchmarks.
To compare the impact of a new Node.js version, we ran each benchmark multiple times (30) on each configuration and on Node.js 16, 18, and 20. When the output is shown as a table, there are two columns that require careful attention:
- improvement - the percentage of improvement relative to the new version
- confidence - tells us if there is enough statistical evidence to validate the improvement
For example, consider the following table results:
confidence improvement accuracy (*) (**) (***)
fs/readfile.js concurrent=1 len=16777216 encoding='ascii' duration=5 *** 67.59 % ±3.80% ±5.12% ±6.79%
fs/readfile.js concurrent=1 len=16777216 encoding='utf-8' duration=5 *** 11.97 % ±1.09% ±1.46% ±1.93%
fs/writefile-promises.js concurrent=1 size=1024 encodingType='utf' duration=5 0.36 % ±0.56% ±0.75% ±0.97%
Be aware that when doing many comparisons the risk of a false-positive result increases.
In this case, there are 10 comparisons, you can thus expect the following amount of false-positive results:
0.50 false positives, when considering a 5% risk acceptance (*, **, ***),
0.10 false positives, when considering a 1% risk acceptance (**, ***),
0.01 false positives, when considering a 0.1% risk acceptance (***)
There is a risk of 0.1% that fs.readfile didn’t improve from Node.js 16 to Node.js 18 (confidence ***). Hence, we
are pretty confident with the results. The table structure can be read as:
-
fs/readfile.js- benchmark file -
concurrent=1 len=16777216 encoding='ascii' duration=5- benchmark options. Each benchmark file can have many options, in this case, it’s reading 1 concurrent file with 16777216 bytes during 5 seconds using ASCII as the encoding method.
For the statistically minded, the script performs an independent/unpaired 2-group t-test, with the null hypothesis that the performance is the same for both versions. The confidence field will show a star if the p-value is less than
0.05. — Writing and Running benchmarks
Benchmark Setup
- Clone the fork Node.js repo
-
Checkout
state-of-nodejsbranch - Create Node.js 16, 18, and 20 binaries
-
Run the
benchmark.shscript
#1
git clone [email protected]:RafaelGSS/node.git
#2
cd node && git checkout state-of-nodejs
#3
nvm install v20.0.0
cp $(which node) ./node20
nvm install v18.16.0
cp $(which node) ./node18
nvm install v16.20.0
cp $(which node) ./node16
#4
./benchmark.shFile System
When upgrading Node.js from 16 to 18, an improvement of 67% was observed when using fs.readfile API with an ascii
encoding and 12% roughly when using utf-8.
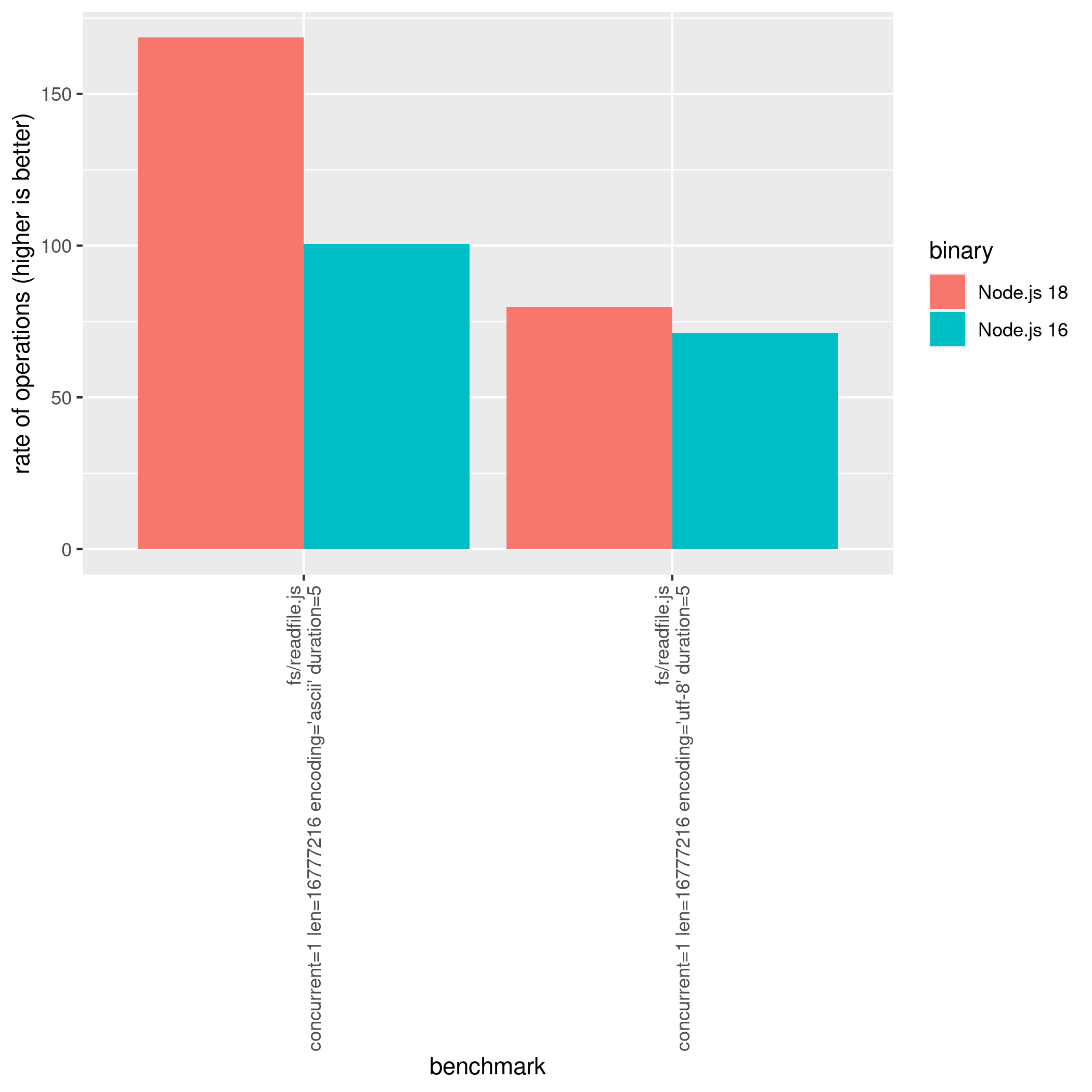
The benchmark results showed that there was an improvement of about 67% in the fs.readfile API with an ascii
encoding and roughly 12% when using utf-8 when upgrading Node.js from version 16 to 18. The file utilized for the
benchmark was created using the following code snippet:
const data = Buffer.alloc(16 * 1024 * 1024, 'x');
fs.writeFileSync(filename, data);
However, there was a regression when using fs.readfile with ascii on Node.js 20 of 27%. This regression has been
reported to the Node.js Performance team, and it is expected to be fixed. On the other hand, fs.opendir,
fs.realpath, and fs.readdir showed improvement from Node.js 18 to Node.js 20. The comparison between Node.js 18 and
20 can be seen in the benchmark result below:
confidence improvement accuracy (*) (**) (***)
fs/bench-opendir.js bufferSize=1024 mode='async' dir='test/parallel' n=100 *** 3.48 % ±0.22% ±0.30% ±0.39%
fs/bench-opendir.js bufferSize=32 mode='async' dir='test/parallel' n=100 *** 7.86 % ±0.29% ±0.39% ±0.50%
fs/bench-readdir.js withFileTypes='false' dir='test/parallel' n=10 *** 8.69 % ±0.22% ±0.30% ±0.39%
fs/bench-realpath.js pathType='relative' n=10000 *** 5.13 % ±0.97% ±1.29% ±1.69%
fs/readfile.js concurrent=1 len=16777216 encoding='ascii' duration=5 *** -27.30 % ±4.27% ±5.75% ±7.63%
fs/readfile.js concurrent=1 len=16777216 encoding='utf-8' duration=5 *** 3.25 % ±0.61% ±0.81% ±1.06%
0.10 false positives, when considering a 5% risk acceptance (*, **, ***),
0.02 false positives, when considering a 1% risk acceptance (**, ***),
0.00 false positives, when considering a 0.1% risk acceptance (***)If you are using Node.js 16, you can use the following comparison between Node.js 16 and Node.js 20
confidence improvement accuracy (*) (**) (***)
fs/bench-opendir.js bufferSize=1024 mode='async' dir='test/parallel' n=100 *** 2.79 % ±0.26% ±0.35% ±0.46%
fs/bench-opendir.js bufferSize=32 mode='async' dir='test/parallel' n=100 *** 5.41 % ±0.27% ±0.35% ±0.46%
fs/bench-readdir.js withFileTypes='false' dir='test/parallel' n=10 *** 2.19 % ±0.26% ±0.35% ±0.45%
fs/bench-realpath.js pathType='relative' n=10000 *** 6.86 % ±0.94% ±1.26% ±1.64%
fs/readfile.js concurrent=1 len=16777216 encoding='ascii' duration=5 *** 21.96 % ±7.96% ±10.63% ±13.92%
fs/readfile.js concurrent=1 len=16777216 encoding='utf-8' duration=5 *** 15.55 % ±1.09% ±1.46% ±1.92%

Events
The EventTarget class showed the most significant improvement on the events side. The benchmark involved dispatching a
million events using EventTarget.prototype.dispatchEvent(new Event('foo')).
Upgrading from Node.js 16 to Node.js 18 can deliver an improvement of nearly 15% in event dispatching performance. But the real jump comes when upgrading from Node.js 18 to Node.js 20, which can yield a performance improvement of up to 200% when there is only a single listener.

The EventTarget class is a crucial component of the Web API and is utilized in various parent features such as
AbortSignal and worker_threads. As a result, optimizations made to this class can potentially impact the performance
of these features, including fetch and AbortController. Additionally, the EventEmitter.prototype.emit API also saw
a notable improvement of approximately 11.5% when comparing Node.js 16 to Node.js 20. A comprehensive comparison is
provided below for your reference:
confidence improvement accuracy (*) (**) (***)
events/ee-emit.js listeners=5 argc=2 n=2000000 *** 11.49 % ±1.37% ±1.83% ±2.38%
events/ee-once.js argc=0 n=20000000 *** -4.35 % ±0.47% ±0.62% ±0.81%
events/eventtarget-add-remove.js nListener=10 n=1000000 *** 3.80 % ±0.83% ±1.11% ±1.46%
events/eventtarget-add-remove.js nListener=5 n=1000000 *** 6.41 % ±1.54% ±2.05% ±2.67%
events/eventtarget.js listeners=1 n=1000000 *** 259.34 % ±2.83% ±3.81% ±5.05%
events/eventtarget.js listeners=10 n=1000000 *** 176.98 % ±1.97% ±2.65% ±3.52%
events/eventtarget.js listeners=5 n=1000000 *** 219.14 % ±2.20% ±2.97% ±3.94%HTTP
The HTTP Servers are one of the most impactful layers of improvement in Node.js. It isn’t a myth that most Node.js applications nowadays run an HTTP Server. So, any change can be easily considered a semver-major and increase the efforts for a compatible improvement in performance.
Therefore, the HTTP server utilized is an http.Server that replies 4 chunks of 256 bytes each containing ‘C’ on each
request, as you can see in this example:
http.createServer((req, res) => {
const n_chunks = 4;
const body = 'C'.repeat();
const len = body.length;
res.writeHead(200, {
'Content-Type': 'text/plain',
'Content-Length': len.toString()
});
for (i = 0, n = (n_chunks - 1); i < n; ++i)
res.write(body.slice(i * step, i * step + step));
res.end(body.slice((n_chunks - 1) * step));
})
// See: https://github.com/nodejs/node/blob/main/benchmark/fixtures/simple-http-server.jsWhen comparing the performance of Node.js 16 and Node.js 18, there is a noticeable 8% improvement. However, upgrading from Node.js 18 to Node.js 20 resulted in a significant improvement of 96.13%.

These benchmark results were collected using
test-double-http benchmarker method.
Which is, a simple Node.js script to send HTTP GET requests:
function run() {
if (http.get) { // HTTP or HTTPS
if (options) {
http.get(url, options, request);
} else {
http.get(url, request);
}
} else { // HTTP/2
const client = http.connect(url);
client.on('error', () => {});
request(client.request(), client);
}
}
run();
By switching to more reliable benchmarking tools such as autocannon or wrk, we observed a significant drop in the
reported improvement — from 96% to 9%.
This indicates that the previous benchmarking method had limitations or errors.
However, the actual performance of the HTTP server has improved, and we need to carefully evaluate the percentage of
improvement with the new benchmarking approach to accurately assess the progress made.
Should I expect a 96%/9% performance improvement in my Express/Fastify application?
Absolutely, not. Frameworks may opt not to use the internal HTTP API — that’s one of the reasons Fastify is… fast! For this reason, another benchmark suite was considered in this report (3. HTTP Servers).
Misc
According to our tests, the startup.js script has demonstrated a significant improvement in the Node.js process
lifecycle, with a 27% boost observed from Node.js version 18 to version 20. This improvement is even more impressive
when compared to Node.js version 16, where the startup time was reduced by 34.75%!
As modern applications increasingly rely on serverless systems, reducing startup time has become a crucial factor in improving overall performance. It’s worth noting that the Node.js team is always working towards optimizing this aspect of the platform, as evidenced by our strategic initiative: https://github.com/nodejs/node/issues/35711.
These improvements in startup time not only benefit serverless applications but also enhance the performance of other Node.js applications that rely on quick boot-up times. Overall, these updates demonstrate the Node.js team’s commitment to enhancing the platform’s speed and efficiency for all users.
$ node-benchmark-compare compare-misc-16-18.csv
confidence improvement accuracy (*) (**) (***)
misc/startup.js count=30 mode='process' script='benchmark/fixtures/require-builtins' *** 12.99 % ±0.14% ±0.19% ±0.25%
misc/startup.js count=30 mode='process' script='test/fixtures/semicolon' *** 5.88 % ±0.15% ±0.20% ±0.26%
misc/startup.js count=30 mode='worker' script='benchmark/fixtures/require-builtins' *** 5.26 % ±0.14% ±0.19% ±0.25%
misc/startup.js count=30 mode='worker' script='test/fixtures/semicolon' *** 3.84 % ±0.15% ±0.21% ±0.27%
$ node-benchmark-compare compare-misc-18-20.csv
confidence improvement accuracy (*) (**) (***)
misc/startup.js count=30 mode='process' script='benchmark/fixtures/require-builtins' *** -4.80 % ±0.13% ±0.18% ±0.23%
misc/startup.js count=30 mode='process' script='test/fixtures/semicolon' *** 27.27 % ±0.22% ±0.29% ±0.38%
misc/startup.js count=30 mode='worker' script='benchmark/fixtures/require-builtins' *** 7.23 % ±0.21% ±0.28% ±0.37%
misc/startup.js count=30 mode='worker' script='test/fixtures/semicolon' *** 31.26 % ±0.33% ±0.44% ±0.58%This benchmark is pretty straightforward. We measure the time elapsed when creating a new [mode] using the given [script] where [mode] can be:
-
process- a new Node.js process -
worker- a Node.js worker_thread
And [script] is divided into:
-
benchmark/fixtures/require-builtins- a script that requires all the Node.js modules -
test/fixtures/semicolon- an empty script — containing a single;(semicolon)
This experiment can be easily reproducible with hyperfine or time:
$ hyperfine --warmup 3 './node16 ./nodejs-internal-benchmark/semicolon.js'
Benchmark 1: ./node16 ./nodejs-internal-benchmark/semicolon.js
Time (mean ± σ): 24.7 ms ± 0.3 ms [User: 19.7 ms, System: 5.2 ms]
Range (min … max): 24.1 ms … 25.6 ms 121 runs
$ hyperfine --warmup 3 './node18 ./nodejs-internal-benchmark/semicolon.js'
Benchmark 1: ./node18 ./nodejs-internal-benchmark/semicolon.js
Time (mean ± σ): 24.1 ms ± 0.3 ms [User: 18.1 ms, System: 6.3 ms]
Range (min … max): 23.6 ms … 25.3 ms 123 runs
$ hyperfine --warmup 3 './node20 ./nodejs-internal-benchmark/semicolon.js'
Benchmark 1: ./node20 ./nodejs-internal-benchmark/semicolon.js
Time (mean ± σ): 18.4 ms ± 0.3 ms [User: 13.0 ms, System: 5.9 ms]
Range (min … max): 18.0 ms … 19.7 ms 160 runs💡 The warmup is necessary to consider the influence of the file system cache
The trace_events module has also undergone a notable performance boost, with a 7% improvement observed when
comparing Node.js version 16 to version 20. It’s worth noting that this improvement was slightly lower, at 2.39%,
when comparing Node.js version 18 to version 20.
Module
require() (or module.require) has long been a culprit of slow Node.js startup times. However, recent performance
improvements suggest that this function has been optimized as well. Between Node.js versions 18 and 20, we observed
improvements of 4.20% when requiring .js files, 6.58% for .json files, and 9.50% when reading
directories - all of which contribute to faster startup times.
Optimizing require() is crucial because it is a function that’s used heavily in Node.js applications. By reducing the
time it takes for this function to execute, we can significantly speed up the entire startup process and improve the
user experience.

Streams
Streams are an incredibly powerful and widely used feature of Node.js. However, between Node.js versions 16 and 18, some
operations related to streams became slower. This includes creating and destroying Duplex, Readable, Transform,
and Writable streams, as well as the .pipe() method for Readable → Writable streams.
The graph below illustrates this regression:
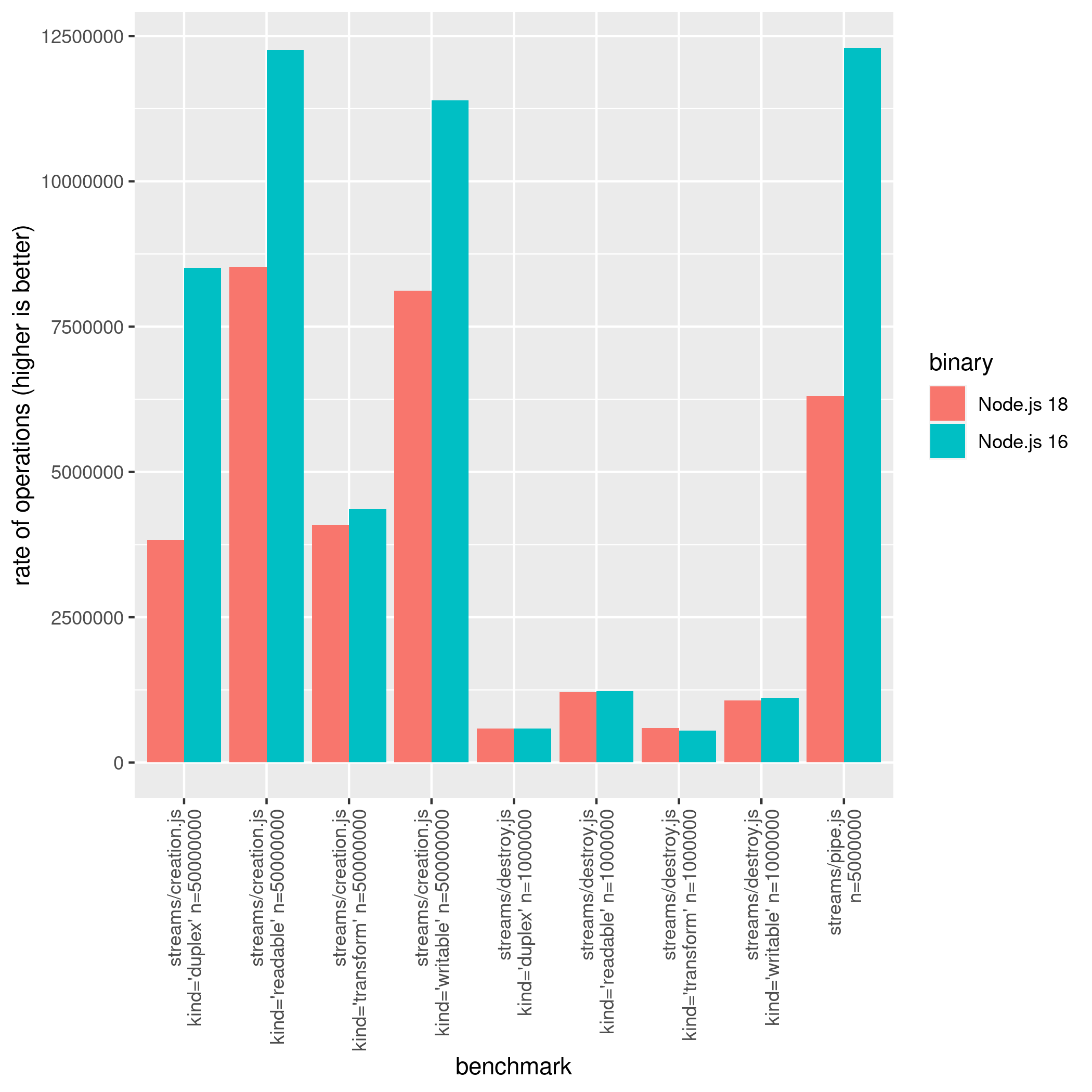
However, this pipe regression was reduced in Node.js 20:
$ node-benchmark-compare compare-streams-18-20.csv
confidence improvement accuracy (*) (**) (***)
streams/creation.js kind='duplex' n=50000000 *** 12.76 % ±4.30% ±5.73% ±7.47%
streams/creation.js kind='readable' n=50000000 *** 3.48 % ±1.16% ±1.55% ±2.05%
streams/creation.js kind='transform' n=50000000 ** -7.59 % ±5.27% ±7.02% ±9.16%
streams/creation.js kind='writable' n=50000000 *** 4.20 % ±0.87% ±1.16% ±1.53%
streams/destroy.js kind='duplex' n=1000000 *** -6.33 % ±1.08% ±1.43% ±1.87%
streams/destroy.js kind='readable' n=1000000 *** -1.94 % ±0.70% ±0.93% ±1.21%
streams/destroy.js kind='transform' n=1000000 *** -7.44 % ±0.93% ±1.24% ±1.62%
streams/destroy.js kind='writable' n=1000000 0.20 % ±1.89% ±2.52% ±3.29%
streams/pipe.js n=5000000 *** 87.18 % ±2.58% ±3.46% ±4.56%
And as you may have noticed, some types of streams (Transform specifically) are regressed in Node.js 20. Therefore,
Node.js 16 still has the fastest streams — for this specific benchmark, please do not read this benchmark result as
‘Node.js streams in v18 and v20 are so slow!’ This is a specific benchmark that may or may not affect your workload. For
instance, if you look at a naive comparison
in the nodejs-bench-operations,
you will see that the following snippet performs better on Node.js 20 than its predecessors:
suite.add('streams.Writable writing 1e3 * "some data"', function () {
const writable = new Writable({
write (chunk, enc, cb) {
cb()
}
})
let i = 0
while(i < 1e3) {
writable.write('some data')
++i
}
})The fact is, the instantiation and destroy methods play an important role in the Node.js ecosystem. Hence, it’s very likely to have a negative impact on some libraries. However, this regression is being monitored closely in the Node.js Performance WG.
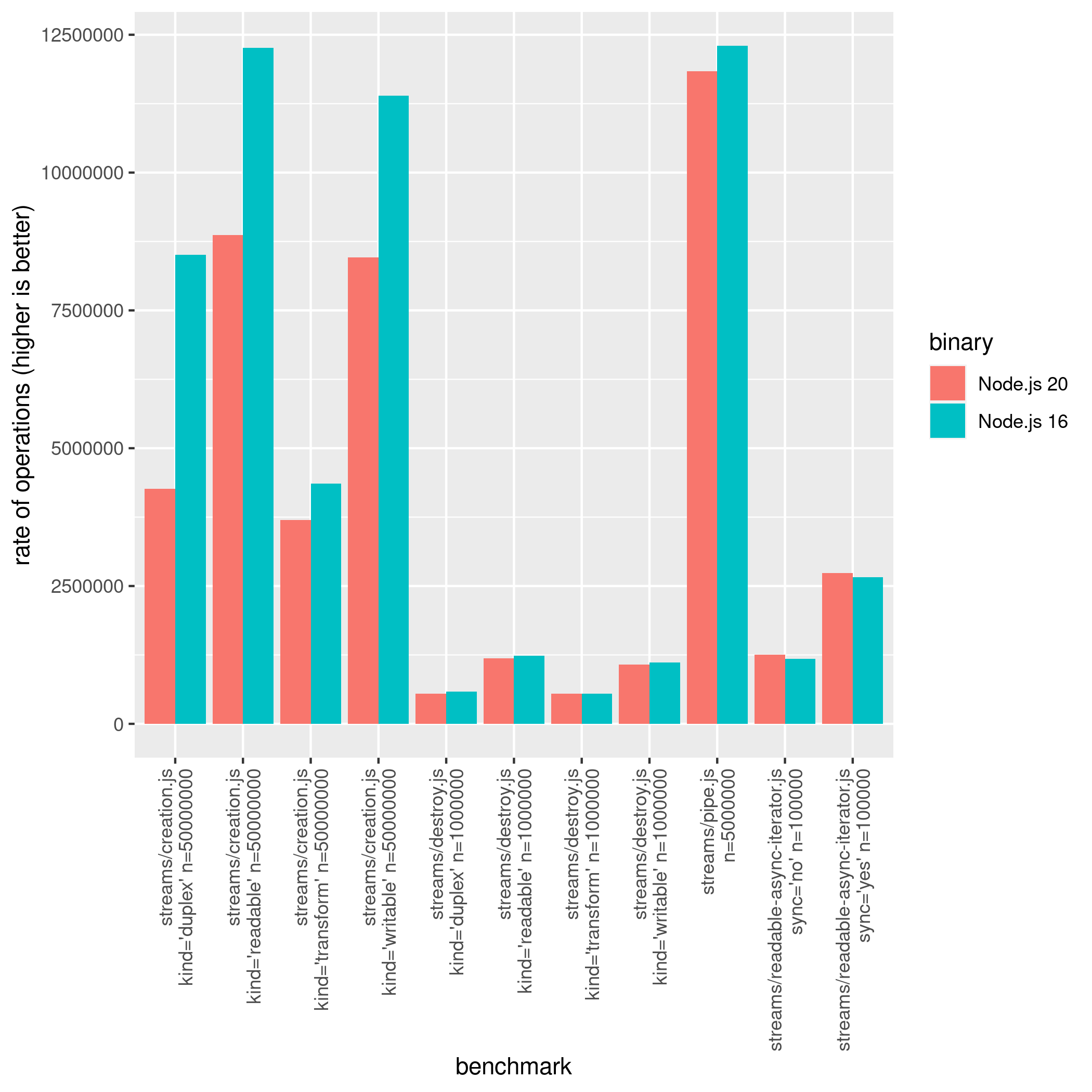
Note that the readable async iterator becomes slightly faster (~6.14%) on Node.js 20.
URL
Since Node.js 18, a new URL parser dependency was added to Node.js — Ada. This addition bumped the Node.js performance when parsing URLs to a new level. Some results could reach up to an improvement of 400%. As a regular user, you may not use it directly. But if you use an HTTP server then it’s very likely to be affected by this performance improvement.
The URL benchmark suite is pretty large. For this reason, only WHATWG URL benchmark results will be covered.
url.parse() and url.resolve() are both deprecated and legacy APIs. Even though its usage is considered a risk for
any Node.js application, developers still use it. Quoting Node.js documentation:
url.parse()uses a lenient, non-standard algorithm for parsing URL strings. It is prone to security issues such as host name spoofing and incorrect handling of usernames and passwords. Do not use with untrusted input. CVEs are not issued forurl.parse()vulnerabilities. Use the WHATWG URL API instead.
If you are curious about the performance changes of url.parse and url.resolve, check out the
State of Node.js Performance 2023 repository.
That said, it’s really interesting to see the results of the new whatwg-url-parse:

Below is a list of URLs used for benchmarking, which were selected based on the benchmark configuration
const urls = {
long: 'http://nodejs.org:89/docs/latest/api/foo/bar/qua/13949281/0f28b/' +
'/5d49/b3020/url.html#test?payload1=true&payload2=false&test=1' +
'&benchmark=3&foo=38.38.011.293&bar=1234834910480&test=19299&3992&' +
'key=f5c65e1e98fe07e648249ad41e1cfdb0',
short: 'https://nodejs.org/en/blog/',
idn: 'http://你好你好.在线',
auth: 'https://user:[email protected]/path?search=1',
file: 'file:///foo/bar/test/node.js',
ws: 'ws://localhost:9229/f46db715-70df-43ad-a359-7f9949f39868',
javascript: 'javascript:alert("node is awesome");',
percent: 'https://%E4%BD%A0/foo',
dot: 'https://example.org/./a/../b/./c',
}With the recent upgrade of Ada 2.0 in Node.js 20, it’s fair to say there’s also a significant improvement when comparing Node.js 18 to Node.js 20:

And the benchmark file is pretty simple:
function useWHATWGWithoutBase(data) {
const len = data.length;
let result = new URL(data[0]); // Avoid dead code elimination
bench.start();
for (let i = 0; i < len; ++i) {
result = new URL(data[i]);
}
bench.end(len);
return result;
}
function useWHATWGWithBase(data) {
const len = data.length;
let result = new URL(data[0][0], data[0][1]); // Avoid dead code elimination
bench.start();
for (let i = 0; i < len; ++i) {
const item = data[i];
result = new URL(item[0], item[1]);
}
bench.end(len);
return result;
}
The only difference is the second parameter that is used as a base when creating/parsing the URL. It’s also worth
mentioning that when a base is passed (withBase=’true’), it tends to perform faster than the regular usage
(new URL(data)). See all the results expanded in
the main repository.
Buffers
In Node.js, buffers are used to handle binary data. Buffers are a built-in data structure that can be used to store raw binary data in memory, which can be useful when working with network protocols, file system operations, or other low-level operations. Overall, buffers are an important part of Node.js and are used extensively throughout the platform for handling binary data.
For those of you who make use directly or indirectly of Node.js buffers, I have good news (mainly for Node.js 20 early adopters).
Besides improving the performance of Buffer.from() Node.js 20 fixed two main regressions from Node.js 18:
-
Buffer.concat()
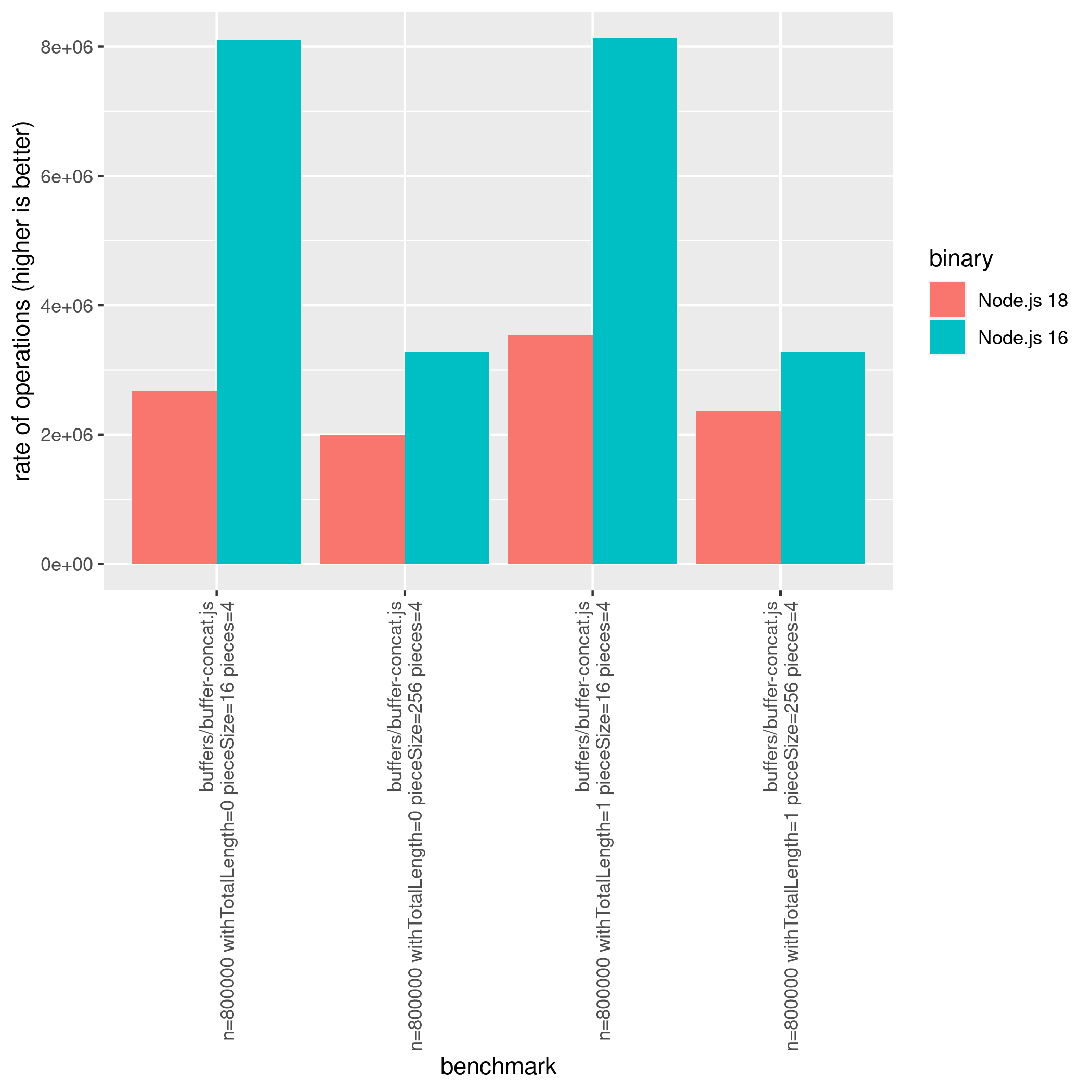
Node.js version 20 has shown significant improvements compared to version 18, and these improvements remain apparent even when compared to version 16:


-
Buffer.toJSON()
From Node.js 16 to Node.js 18, a drop of 88% in the performance of Buffer.toJSON was observed:
$ node-benchmark-compare compare-buffers-16-18.csv
confidence improvement accuracy (*) (**) (***)
buffers/buffer-tojson.js len=256 n=10000 *** -81.12 % ±1.25% ±1.69% ±2.24%
buffers/buffer-tojson.js len=4096 n=10000 *** -88.39 % ±0.69% ±0.93% ±1.23%However, this regression was fixed and improved in Node.js 20 by orders of magnitude!
$ node-benchmark-compare compare-buffers-18-20.csv
confidence improvement accuracy (*) (**) (***)
buffers/buffer-tojson.js len=256 n=10000 *** 482.81 % ±7.02% ±9.42% ±12.42%
buffers/buffer-tojson.js len=4096 n=10000 *** 763.34 % ±5.22% ±7.04% ±9.34%Therefore, it’s correct to state that Node.js 20 is the fastest version of Node.js in dealing with buffers.
See the full comparison between Node.js 20 and Node.js 18 below:
$ node-benchmark-compare compare-buffers-18-20.csv
confidence improvement accuracy (*) (**) (***)
buffers/buffer-base64-decode.js size=8388608 n=32 *** 1.66 % ±0.10% ±0.14% ±0.18%
buffers/buffer-base64-encode.js n=32 len=67108864 *** -0.44 % ±0.17% ±0.23% ±0.30%
buffers/buffer-compare.js n=1000000 size=16 *** -3.14 % ±0.82% ±1.09% ±1.41%
buffers/buffer-compare.js n=1000000 size=16386 *** -15.56 % ±5.97% ±7.95% ±10.35%
buffers/buffer-compare.js n=1000000 size=4096 -2.63 % ±3.09% ±4.11% ±5.35%
buffers/buffer-compare.js n=1000000 size=512 *** -6.15 % ±1.28% ±1.71% ±2.24%
buffers/buffer-concat.js n=800000 withTotalLength=0 pieceSize=1 pieces=16 *** 300.67 % ±0.71% ±0.95% ±1.24%
buffers/buffer-concat.js n=800000 withTotalLength=0 pieceSize=1 pieces=4 *** 212.56 % ±4.81% ±6.47% ±8.58%
buffers/buffer-concat.js n=800000 withTotalLength=0 pieceSize=16 pieces=16 *** 287.63 % ±2.47% ±3.32% ±4.40%
buffers/buffer-concat.js n=800000 withTotalLength=0 pieceSize=16 pieces=4 *** 216.54 % ±1.24% ±1.66% ±2.17%
buffers/buffer-concat.js n=800000 withTotalLength=0 pieceSize=256 pieces=16 *** 38.44 % ±1.04% ±1.38% ±1.80%
buffers/buffer-concat.js n=800000 withTotalLength=0 pieceSize=256 pieces=4 *** 91.52 % ±3.26% ±4.38% ±5.80%
buffers/buffer-concat.js n=800000 withTotalLength=1 pieceSize=1 pieces=16 *** 192.63 % ±0.56% ±0.74% ±0.97%
buffers/buffer-concat.js n=800000 withTotalLength=1 pieceSize=1 pieces=4 *** 157.80 % ±1.52% ±2.02% ±2.64%
buffers/buffer-concat.js n=800000 withTotalLength=1 pieceSize=16 pieces=16 *** 188.71 % ±2.33% ±3.12% ±4.10%
buffers/buffer-concat.js n=800000 withTotalLength=1 pieceSize=16 pieces=4 *** 151.18 % ±1.13% ±1.50% ±1.96%
buffers/buffer-concat.js n=800000 withTotalLength=1 pieceSize=256 pieces=16 *** 20.83 % ±1.29% ±1.72% ±2.25%
buffers/buffer-concat.js n=800000 withTotalLength=1 pieceSize=256 pieces=4 *** 59.13 % ±3.18% ±4.28% ±5.65%
buffers/buffer-from.js n=800000 len=100 source='array' *** 3.91 % ±0.50% ±0.66% ±0.87%
buffers/buffer-from.js n=800000 len=100 source='arraybuffer-middle' *** 11.94 % ±0.65% ±0.86% ±1.13%
buffers/buffer-from.js n=800000 len=100 source='arraybuffer' *** 12.49 % ±0.77% ±1.03% ±1.36%
buffers/buffer-from.js n=800000 len=100 source='buffer' *** 7.46 % ±1.21% ±1.62% ±2.12%
buffers/buffer-from.js n=800000 len=100 source='object' *** 12.70 % ±0.84% ±1.12% ±1.47%
buffers/buffer-from.js n=800000 len=100 source='string-base64' *** 2.91 % ±1.40% ±1.88% ±2.46%
buffers/buffer-from.js n=800000 len=100 source='string-utf8' *** 12.97 % ±0.77% ±1.02% ±1.33%
buffers/buffer-from.js n=800000 len=100 source='string' *** 16.61 % ±0.71% ±0.95% ±1.25%
buffers/buffer-from.js n=800000 len=100 source='uint16array' *** 5.64 % ±0.84% ±1.13% ±1.48%
buffers/buffer-from.js n=800000 len=100 source='uint8array' *** 6.75 % ±0.95% ±1.28% ±1.68%
buffers/buffer-from.js n=800000 len=2048 source='array' 0.03 % ±0.33% ±0.43% ±0.56%
buffers/buffer-from.js n=800000 len=2048 source='arraybuffer-middle' *** 11.73 % ±0.55% ±0.74% ±0.96%
buffers/buffer-from.js n=800000 len=2048 source='arraybuffer' *** 12.85 % ±0.55% ±0.73% ±0.96%
buffers/buffer-from.js n=800000 len=2048 source='buffer' *** 7.66 % ±1.28% ±1.70% ±2.21%
buffers/buffer-from.js n=800000 len=2048 source='object' *** 11.96 % ±0.90% ±1.20% ±1.57%
buffers/buffer-from.js n=800000 len=2048 source='string-base64' *** 4.10 % ±0.46% ±0.61% ±0.79%
buffers/buffer-from.js n=800000 len=2048 source='string-utf8' *** -1.30 % ±0.71% ±0.96% ±1.27%
buffers/buffer-from.js n=800000 len=2048 source='string' *** -2.23 % ±0.93% ±1.25% ±1.64%
buffers/buffer-from.js n=800000 len=2048 source='uint16array' *** 6.89 % ±1.44% ±1.91% ±2.49%
buffers/buffer-from.js n=800000 len=2048 source='uint8array' *** 7.74 % ±1.36% ±1.81% ±2.37%
buffers/buffer-tojson.js len=0 n=10000 *** -11.63 % ±2.34% ±3.11% ±4.06%
buffers/buffer-tojson.js len=256 n=10000 *** 482.81 % ±7.02% ±9.42% ±12.42%
buffers/buffer-tojson.js len=4096 n=10000 *** 763.34 % ±5.22% ±7.04% ±9.34%Text Encoding and Decoding
TextDecoder and TextEncoder are two JavaScript classes that are part of the Web APIs specification and are available in modern web browsers and Node.js. Together, TextDecoder and TextEncoder provide a simple and efficient way to work with text data in JavaScript, allowing developers to perform various operations involving strings and character encodings.
Decoding and Encoding becomes considerably faster than in Node.js 18. With the addition of simdutf for UTF-8 parsing the observed benchmark, results improved by 364% (an extremely impressive leap) when decoding in comparison to Node.js 16.
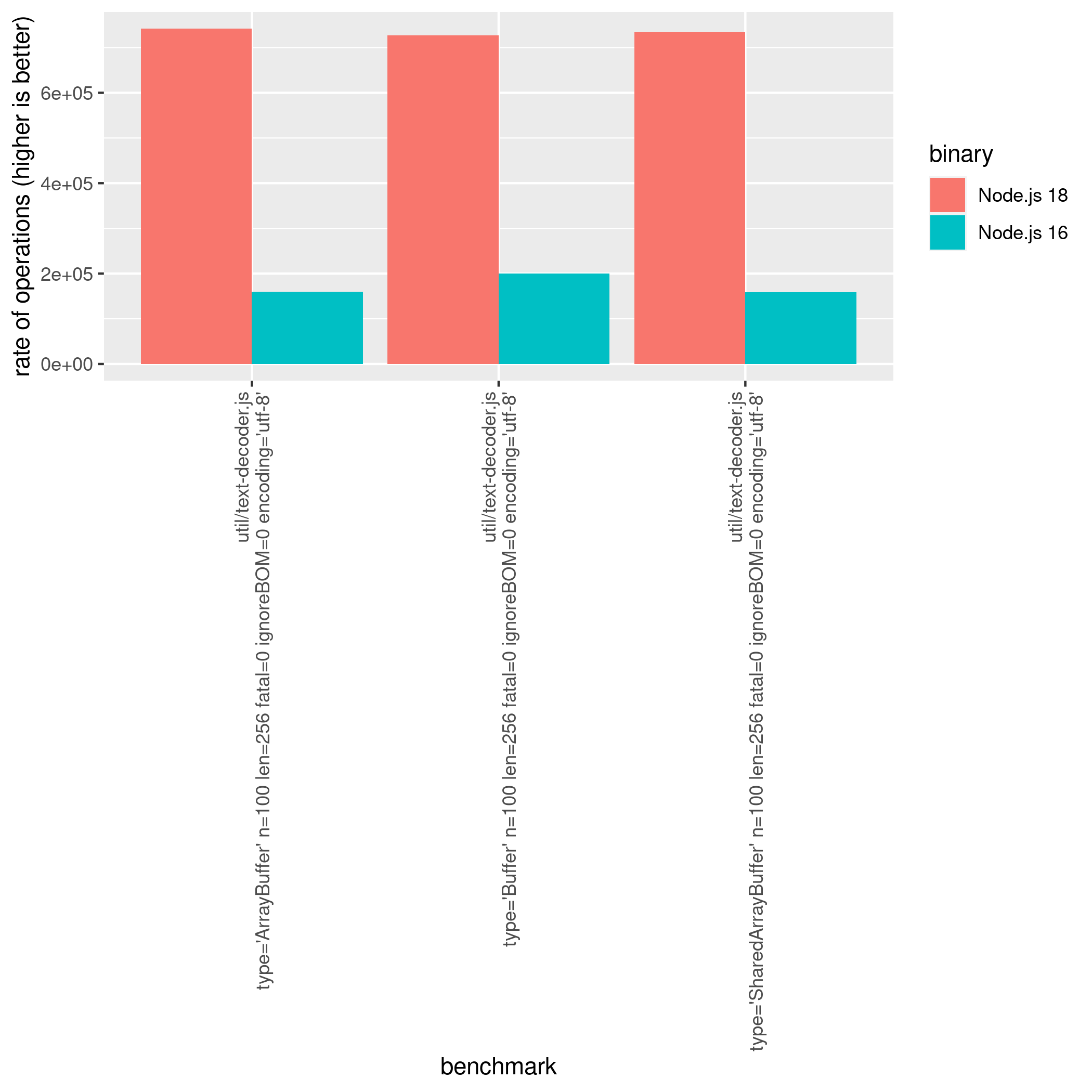
Those improvements got even better on Node.js 20, with a performance improvement of 25% in comparison to Node.js 18. See the full results in the state-of-nodejs-performance-2023 repository.
Performance improvements were also observed when comparing encoding methods on Node.js 18. From Node.js 16 to Node.js
18, the TextEncoder.encodeInto reached 93.67% of improvement in the current observation (using ascii with a
string length of 256):

Node.js Bench Operations
The benchmarking operations in Node.js have always piqued my curiosity. As someone who enjoys exploring the intricacies of Node.js and its underlying technology, I find it fascinating to delve into the details of these operations, particularly those related to the V8 engine. In fact, I often like to share my findings with others through talks and workshops delivered by NearForm, a company I’m affiliated with. If you’re interested, you can find more information about my presentations on this topic by clicking this link.
In addition, these benchmarks will use the ops/sec metric, which basically means the number of operations that were
performed in one second. It’s important to emphasize that this can only mean a very small fraction of your computing
time. If you have read my previous article
(Preparing and Evaluating Benchmarks)
you should remember the ‘Evaluating Results’ section, where I approach the problem with ops/sec in real-world
applications — if not, you should consider returning to it.
Parsing Integers
Parsing strings to numbers can be accomplished using either + or parseInt(x, 10). Previous benchmark results
showed that using + was faster than parseInt(x, 10) in earlier versions of Node.js, as illustrated in the table
below:
| name | ops/sec | samples |
|---|---|---|
| Using parseInt(x, 10) - small number (2 len) | 283,768,532 | 91 |
| Using parseInt(x, 10) - big number (10 len) | 21,307,115 | 100 |
| Using + - small number (2 len) | 849,906,952 | 100 |
| Using + - big number (10 len) | 849,173,336 | 97 |
However, with the release of Node.js 20 and the new V8 version (11.4), both operations have become equivalent in terms of performance, as shown in the updated benchmark results below:
| name | ops/sec | samples |
|---|---|---|
| Using parseInt(x, 10) - small number (2 len) | 856,413,575 | 98 |
| Using parseInt(x, 10) - big number (10 len) | 856,754,259 | 96 |
| Using + - small number (2 len) | 857,364,191 | 98 |
| Using + - big number (10 len) | 857,511,971 | 96 |
Super vs This
One of the interesting benchmarks that have changed with the addition of Node.js 20 is the usage of this or super in
classes, as you can see in the example underneath:
class Base {
foo () {
return 10 * 1e2
}
}
class SuperClass extends Base {
bar () {
const tmp = 20 * 23
return super.foo() + tmp
}
}
class ThisClass extends Base {
bar () {
const tmp = 20 * 23
return this.foo() + tmp
}
}
The comparison between super and this in Node.js 18 was producing the following operations per second (ops/sec):
| name | ops/sec | samples |
|---|---|---|
| Using super | 159,426,608 | 96 |
| Using this | 160,092,440 | 91 |
There isn’t a significant difference between both approaches and on Node.js 20. This statement holds with a slight difference:
| name | ops/sec | samples |
|---|---|---|
| Using super | 850,760,436 | 97 |
| Using this | 853,619,840 | 99 |
Based on the benchmark results, it appears that there has been a significant increase in performance when using this
on Node.js 20 compared to Node.js 18. This increase is quite remarkable, with this achieving an impressive
853,619,840 ops/sec on Node.js 20 compared to only 160,092,440 ops/sec on Node.js 18, which is, 433% better!
Apparently, it has the same property access method as a regular object: obj.property1. Also, note that both operations
were tested in the same dedicated environment. Therefore, it’s unlikely to have occurred by chance.
Property Access
There are various ways to add properties to objects in JavaScript, each with its own purpose and sometimes ambiguous in nature. As a developer, you may wonder about the efficiency of property access in each of these methods.
The good news is that the nodejs-bench-operations repository includes a comparison of these methods, which sheds light
on their performance characteristics. In fact, this benchmarking data reveals that the property access in Node.js 20 has
seen significant improvements, particularly when using objects with writable: true and
enumerable/configurable: false properties.
const myObj = {};
Object.defineProperty(myObj, 'test', {
writable: true,
value: 'Hello',
enumerable: false,
configurable: false,
});
myObj.test // How fast is the property access?On Node.js 18 the property access (myObj.test) was producing 166,422,265 ops/sec. However, under the same circumstances, Node.js 20 is producing 857,316,403 ops/sec! This and other particularities around property access can be found in the following benchmark results:
- Property getter access v18 / v20
- Property setter access v18 / v20
- Property access after shape transition v18 / v20
Array.prototype.at
Array.prototype.at(-1) is a method that was introduced in the ECMAScript 2021 specification. It allows you to access
the last element of an array without knowing its length or using negative indices, which can be a useful feature in
certain use cases. In this way, the at() method provides a more concise and readable way to access the last element of
an array, compared to traditional methods like array[array.length - 1].
On Node.js 18 this access was considerably slower in comparison to Array[length-1]:
| name | ops/sec | samples |
|---|---|---|
| Length = 100 - Array.at | 26,652,680 | 99 |
| Length = 10_000 - Array.at | 26,317,564 | 97 |
| Length = 1_000_000 - Array.at | 27,187,821 | 98 |
| Length = 100 - Array[length - 1] | 848,118,011 | 98 |
| Length = 10_000 - Array[length - 1] | 847,958,319 | 100 |
| Length = 1_000_000 - Array[length - 1] | 847,796,498 | 101 |
Since Node.js 19, Array.prototype.at is equivalent to the old-fashioned Array[length-1] as the table below suggests:
| name | ops/sec | samples |
|---|---|---|
| Length = 100 - Array.at | 852,980,778 | 99 |
| Length = 10_000 - Array.at | 854,299,272 | 99 |
| Length = 1_000_000 - Array.at | 853,374,694 | 98 |
| Length = 100 - Array[length - 1] | 854,589,197 | 95 |
| Length = 10_000 - Array[length - 1] | 856,122,244 | 95 |
| Length = 1_000_000 - Array[length - 1] | 856,557,974 | 99 |
String.prototype.includes
Most people know that RegExp is very often the source of many bottlenecks in any kind of application. For instance,
you might want to check if a certain variable contains application/json.And while you can do it in several manners,
most of the time you will end up using either:
-
/application\/json/.test(text)- RegEx
or
-
text.includes('application/json')- String.prototype.includes
What some of you may not know is that String.prototype.includes is pretty much as slow as RegExp on Node.js 16.
| name | ops/sec | samples |
|---|---|---|
| Using includes | 16,056,204 | 97 |
| Using indexof | 850,710,330 | 100 |
| Using RegExp.test | 15,227,370 | 98 |
| Using RegExp.text with cached regex pattern | 15,808,350 | 97 |
| Using new RegExp.test | 4,945,475 | 98 |
| Using new RegExp.test with cached regex pattern | 5,944,679 | 100 |
However, since Node.js 18 this behavior was fixed.
| name | ops/sec | samples |
|---|---|---|
| Using includes | 856,127,951 | 101 |
| Using indexof | 856,709,023 | 98 |
| Using RegExp.test | 16,623,756 | 98 |
| Using RegExp.text with cached regex pattern | 16,952,701 | 99 |
| Using new RegExp.test | 4,704,351 | 95 |
| Using new RegExp.test with cached regex pattern | 5,660,755 | 95 |
Crypto.verify
In Node.js, the crypto module provides a set of cryptographic functionalities that can be used for various purposes,
such as creating and verifying digital signatures, encrypting and decrypting data, and generating secure random numbers.
One of the methods available in this module is crypto.verify(), which is used to verify a digital signature generated
by the crypto.sign() method.
Node.js 14 (End-of-Life) uses OpenSSL 1.x. On Node.js 16 we’ve had the addition of the QUIC protocol, but still using OpenSSL version 1. However, in Node.js 18 we’ve updated OpenSSL to version 3.x (over QUIC), and a regression was found after Node.js 18 that reduced from 30k ops/sec to 6~7k ops/sec. As I’ve mentioned in the tweet, it’s very likely to be caused by the new OpenSSL version. Again, our team is looking into it and if you have any insight on this, feel free to comment on the issue: https://github.com/nodejs/performance/issues/72.
Node.js performance initiatives
The Node.js team has always been careful to ensure that its APIs and core functionalities are optimized for speed and resource usage.
In order to further enhance the performance of Node.js, the team has recently introduced a new strategic initiative called ‘Performance’, which is chaired by Yagiz Nizipli. This initiative is aimed at identifying and addressing performance bottlenecks in the Node.js runtime and core modules, as well as improving the overall performance and scalability of the platform.
In addition to the Performance initiative, there are several other initiatives currently underway that are focused on optimizing different aspects of Node.js. One of these initiatives is the ‘Startup Snapshot’ initiative, which is chaired by Joyee. This initiative is aimed at reducing the startup time of Node.js applications, which is a critical factor in improving the overall performance and user experience of web applications.
Therefore, if you are interested in this subject, consider joining the meetings every other week, and feel free to send
a message in the #nodejs-core-performance channel on the
OpenJS Foundation Slack.
Things to keep an eye on
Besides the strategic initiatives, there are some pull requests that are very likely to have a great impact on the Node.js performance — at the moment I’m writing the below post (it isn’t merged yet):
- Node.js Errors - https://github.com/nodejs/node/pull/46648
Errors are very expensive to create in Node.js. It’s very often a source of bottlenecks in Node.js applications. As an example, I conducted research on the implementation of fetch in Node.js (undici) and discovered one of the villains in the Node.js WebStreams implementation is error creation. Hence, by optimizing error objects in Node.js, we can improve the overall efficiency of the platform and reduce the risk of bottlenecks.
- Pointer compression builds - https://github.com/nodejs/build/issues/3204
Pointer compression is a technique used in computer programming to reduce the memory usage of programs that make use of many pointers. While it doesn’t improve performance directly, it can indirectly improve performance by reducing cache misses and page faults. This certainly can reduce some infra costs, as described in the issue thread.
-
Increase default
--max-semi-space-size- https://github.com/nodejs/node/pull/47277
An issue was created in March 2022 suggesting increasing the V8
max_semi_space_size with the objective to reduce the Garbage Collection (Scavenge specifically) runs and increasing
the overall throughput in the web tooling benchmark. We’re still evaluating its impact and it may or may not arrive in
Node.js 21.
-
bump
highWaterMarkvalue on Node.js Readable/Writable streams - https://github.com/nodejs/node/pull/46608
This PR increases the default value for highWaterMark value in Node.js streams. It’s expected to perceive a
performance improvement in the Node.js stream usage with default options. This PR however, is a semver-major change
and should arrive on Node.js 21. For a detailed benchmark result, wait for: ‘State of Node.js Performance 2023 - P2’ at
the end of the year.
Conclusion
Despite some regressions in the Node.js streams and crypto module, Node.js 20 boasts significant improvements in performance compared to previous versions. Notable enhancements have been observed in JavaScript operations such as property access, URL parsing, buffers/text encoding and decoding, startup/process lifecycle time, and EventTarget, among others.
The Node.js performance team (nodejs/performance) has expanded its scope, leading to greater contributions in optimizing performance with each new version. This trend indicates that Node.js will continue to become faster over time.
It’s worth mentioning that the benchmark tests focus on specific operations, which may or may not directly impact your specific use case. Therefore, I strongly recommend reviewing all the benchmark results in the state-of-nodejs-performance repository and ensuring that these operations align with your business requirements.
Acknowledgments
I would like to express my sincere gratitude to all the reviewers who took the time to provide valuable feedback on my blog post. Thank you for your time, expertise, and constructive comments.
It’s also worth noting that I continue to contribute to open-source projects in my free time out of love for the community. If my work has positively impacted you and you’d like to express your appreciation, consider sponsoring me on GitHub 💚.